

概述
前几天写了一篇使用dlvm部署DeepSeek的文章:使用DLVM本地部署DeepSeek(未完待续) 但由于网络原因未能完成,今天借此机会继续完善补充。
排坑
先说一下上次部署过程遇到的一些坑
- 由于国内访问不了
huggingface需要修改模型下载的平台,修改之后再启动容器;
export HF_ENDPOINT=https://hf-mirror.com
export XINFERENCE_MODEL_SRC=modelscope启动容器的命令优化了下:
docker run -d \
--shm-size=128g \
--name xinference \
-v /data/xinference/log:/data/xinference/logs \
-v /data/models:/data/models \
-e XINFERENCE_HOME=/data/xinference \
-p 9997:9997 \
xprobe/xinference:latest \
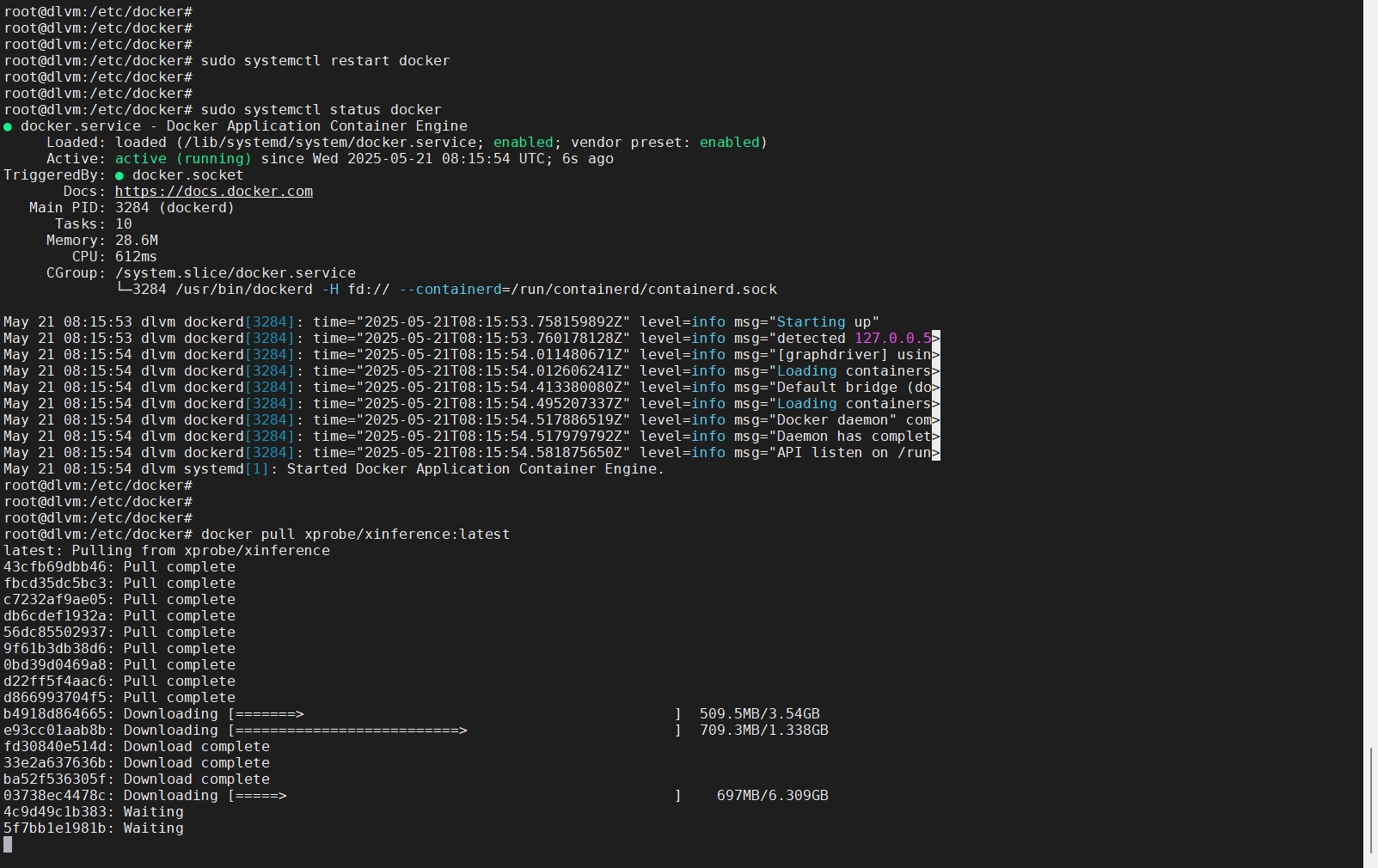
xinference-local -H 0.0.0.0 --log-level debug- 模型可以通过魔搭社区去下载,在前端直接启动可能会导致下载不成功;比如我下载的这个 glm-4-9b-chat-hf 模型,进到容器的模型路径下
modelscope download --model ZhipuAI/glm-4-9b-chat-hf02.jpg)
- Docker容器里面的网络必须要能通互联网,可以使用wget验证,否则上面的模型不可能下载!
01.jpg)
启动模型
上面我已手动将glm-4-9b-chat-hf下载好了,右下角可以更改语言为中文。
03.jpg)
点击小火箭启动
04.jpg)
等待启动完成后就可以在运行模型里面看到它正在运行,
05.jpg)
点击操作下面的启动 Web UI,进入后就可以使用。
06.jpg)
今天太晚了,改天再写继续完善…

0