

概述
该系统采用 Dify 作为用户交互平台,Xinference作为推理框架,开发 RAG(Retrieval-Augmented Generation) 应用,实现对私有知识库的智能问答功能。功能测试把所有组件均部署在 DLVM 虚拟机上(生产环境可以分开部署)
组件详解
- Dify(开源 LLM 应用开发平台)
功能: 提供用户界面,接收用户查询并展示生成的答案。
私有知识库内容: 存储企业内部的文档资源,包括 .txt、.doc、.pdf 等格式。
作用: 为问答系统提供信息检索的数据源。
- Xinference(推理框架)
功能: 管理和调度模型推理任务,提供 API 接口供 Dify调用。
作用: 作为模型推理的核心,协调各模型的工作流程。
- 模型组合text2vec-base-multilingual(嵌入式模型)
功能: 将用户查询和文档内容转换为向量表示,支持多语言文本处理。
作用: 实现文本的向量化表示,便于相似度计算。
- bge-reranker-base(重排序模型)
功能: 对检索到的文档进行重排序,提升与用户查询的相关性。
作用: 优化检索结果的排序,确保最相关的文档优先。
- deepseek-r1-distill-qwen(大语言模型)
功能: 生成自然语言答案,结合检索结果和用户查询,提供准确的回答。
作用: 生成符合用户需求的自然语言响应。
- DLVM
VMware预制的深度学习虚拟机,作为以上组件软件安装系统
导入模板
将下载的ovf模板正常导入
虚拟机命名
选择集群
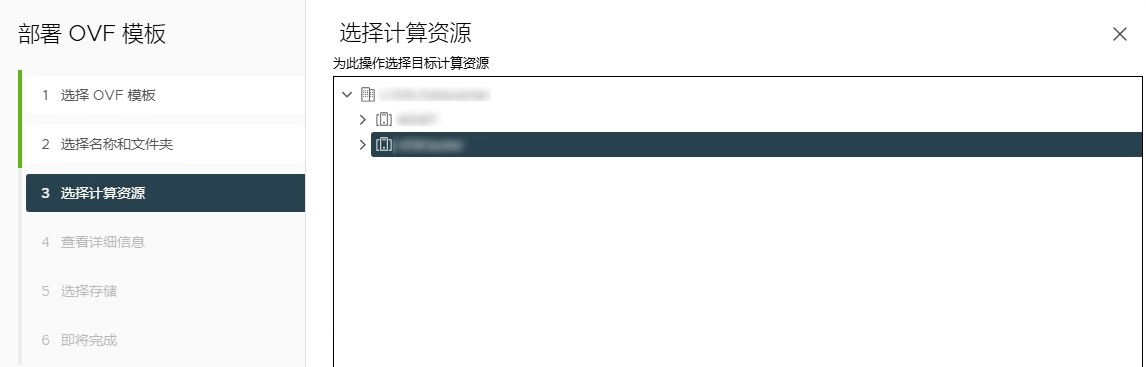
提示 在所选模板中检测到问题。详细信息: – -1:-1:VALUE_ILLEGAL: 在 [vmx-21] 中没有受支持的硬件版本;受支持的: [vmx-04, vmx-07, vmx-08, vmx-09, vmx-10, vmx-11, vmx-12, vmx-13, vmx-14, vmx-15, vmx-16, vmx-17, vmx-18, vmx-19]。
这是由于当前vSphere的版本较低,与该ovf模板中.vmx文件中的VirtualSystemType参数不兼容导致。
根据上面的提示可见,当前最高支持vmx-19,修改.vmx文件,搜索关键词:vmx-,将其数值修改为当前支持的范围内,如修改为 vmx-19,然后重新导入ovf模板。

虚拟机详情
许可协议

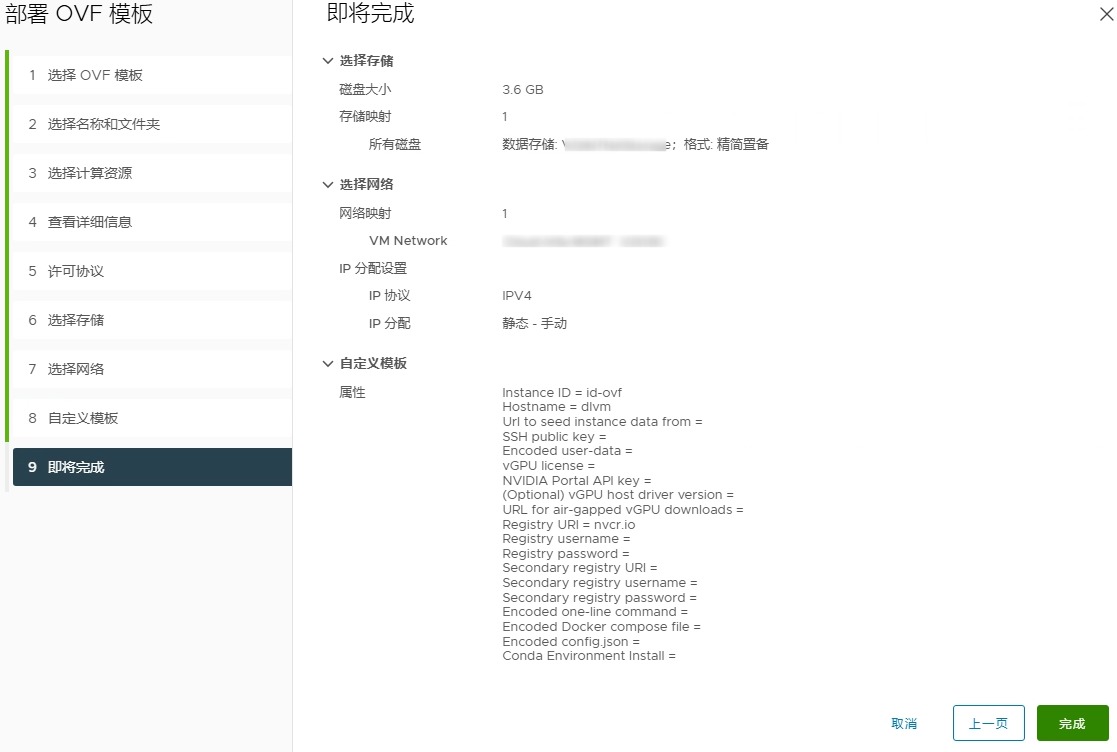
选择存储
选择网络
配置主机名,可以输入虚拟机hostname,默认是dlvm
配置初始密码
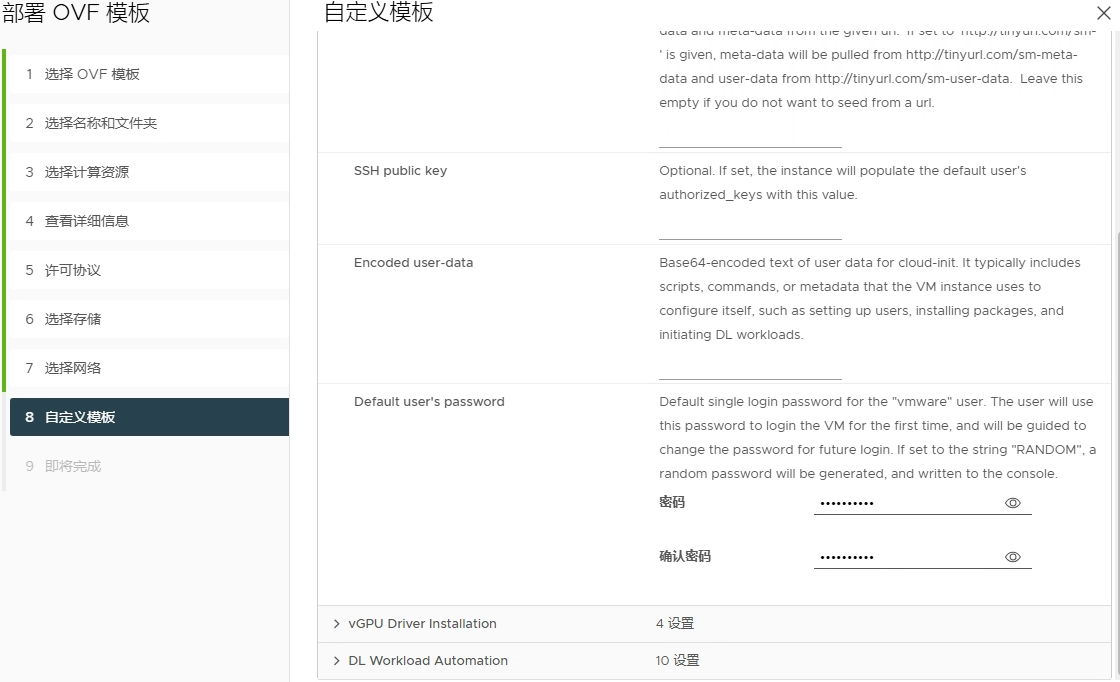
完成,开始导入
由于该环境中没有GPU,故无法针对GPU场景实操记录,待有机会进行补充完善。
配置网络
导入完成后启动虚拟机,默认用户名是 vmware 密码是之前设置的初始密码,开机之后会提示修改默认密码。
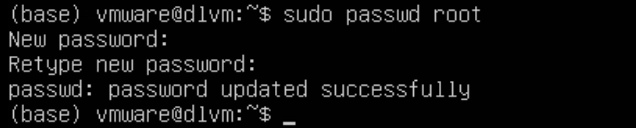
登录完成后并配置一下root密码
配置IP地址
sudo vi /etc/netpln/50-cloud-init.yaml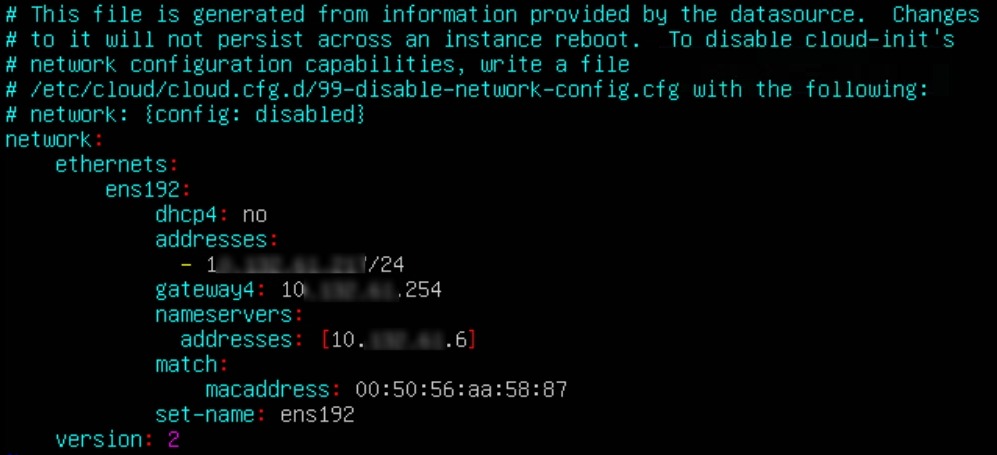
使其网络配置立即生效
sudo netplan apply由于环境中是通过代理上互联网,需要配置一下代理。
# 编辑 .bashrc
sudo vi ~/.bashrc
# 末端添加
export http_proxy="http://your-proxy-server:port"
export https_proxy="http://your-proxy-server:port"
# 刷新.bashrc
sudo source ~/.bashrc配置docker加速
sudo vi /etc/docker/daemon.json将配置贴入
{
"registry-mirrors": [
"https://docker.1panelproxy.com",
"https://2a6bf1988cb6428c877f723ec7530dbc.mirror.swr.myhuaweicloud.com",
"https://docker.m.daocloud.io",
"https://hub-mirror.c.163.com",
"https://mirror.baidubce.com",
"https://your_preferred_mirror",
"https://dockerhub.icu",
"https://docker.registry.cyou",
"https://docker-cf.registry.cyou",
"https://dockercf.jsdelivr.fyi",
"https://docker.jsdelivr.fyi",
"https://dockertest.jsdelivr.fyi",
"https://mirror.aliyuncs.com",
"https://dockerproxy.com",
"https://mirror.baidubce.com",
"https://docker.m.daocloud.io",
"https://docker.nju.edu.cn",
"https://docker.mirrors.sjtug.sjtu.edu.cn",
"https://docker.mirrors.ustc.edu.cn",
"https://mirror.iscas.ac.cn",
"https://docker.rainbond.cc"
]
}重新加载配置文件并重启docker
sudo systemctl daemon-reload
sudo systemctl restart docker为了方便操作,后续我将使用 MobaXterm 通过 SSH连接至服务器。
Xinference 部署配置
设置模型来源modelscop
XINFERENCE_MODEL_SRC=modelscop
docker pull xprobe/xinference:latest镜像很大,需要较长的时间,耐心等待

pull 完后运行
docker run -d \
--shm-size=128g \
--name xinference \
-v /data/xinference/data/.xinference:/root/.xinference \
-v /data/xinference/data/.cache/huggingface:/root/.cache/huggingface \
-v /data/xinference/data/.cache/modelscope:/root/.cache/modelscope \
-v /data/xinference/log:/workspace/xinference/logs \
-v /data/xinference/huggingface:/data/xinference/huggingface \
-e XINFERENCE_HOME=/data/xinference \
-p 9997:9997 \
xprobe/xinference:latest \
xinference-local -H 0.0.0.0 --log-level debug命令解析
- dockerrun-d:以后台模式运行容器。
- –shm-size=128g:设置容器的共享内存大小为128GB。
- –namexinference:为容器指定名称为xinference。
- -v/data/xinference/data/.xinference:/root/.xinference:将宿主机的/data/xinference/data/.xinference目录挂载到容器的/root/.xinference目录,用于持久化Xinference的配置和缓存。
- -v/data/xinference/data/.cache/huggingface:/root/.cache/huggingface:将宿主机的HuggingFace缓存目录挂载到容器中,以便共享模型缓存。
- -v/data/xinference/data/.cache/modelscope:/root/.cache/modelscope:将宿主机的ModelScope缓存目录挂载到容器中,以便共享模型缓存。
- -v/data/xinference/log:/workspace/xinference/logs:将宿主机的日志目录挂载到容器中,用于存储运行日志。
- -v/data/xinference/huggingface:/data/xinference/huggingface:将宿主机的HuggingFace模型目录挂载到容器中,以便共享模型文件。
- -eXINFERENCE_HOME=/data/xinference:设置环境变量XINFERENCE_HOME,指定Xinference的主目录。
- -p9997:9997:将容器的9997端口映射到宿主机的9997端口,用于外部访问服务。
- xprobe/xinference:latest:指定使用名为xprobe/xinference的最新版本镜像。
- xinference-local-H0.0.0.0–log-leveldebug:在容器内启动Xinference服务,监听所有网络接口,并设置日志级别为调试。
- –gpusall:指定容器使用所有可用的GPU资源。(当前无GPU,则不附加该参数)
等待镜像up,登录xinference 使用9997 端口,左下角可以设置语言支持中文和英文。
部署Dify应用开发平台
使用git clone 到DLVM
git clone https://github.com/langgenius/dify.git
运行 docker compose up -d 启动Dify开发平台
cd dify/docker
cp .env.example .env
docker compose up -d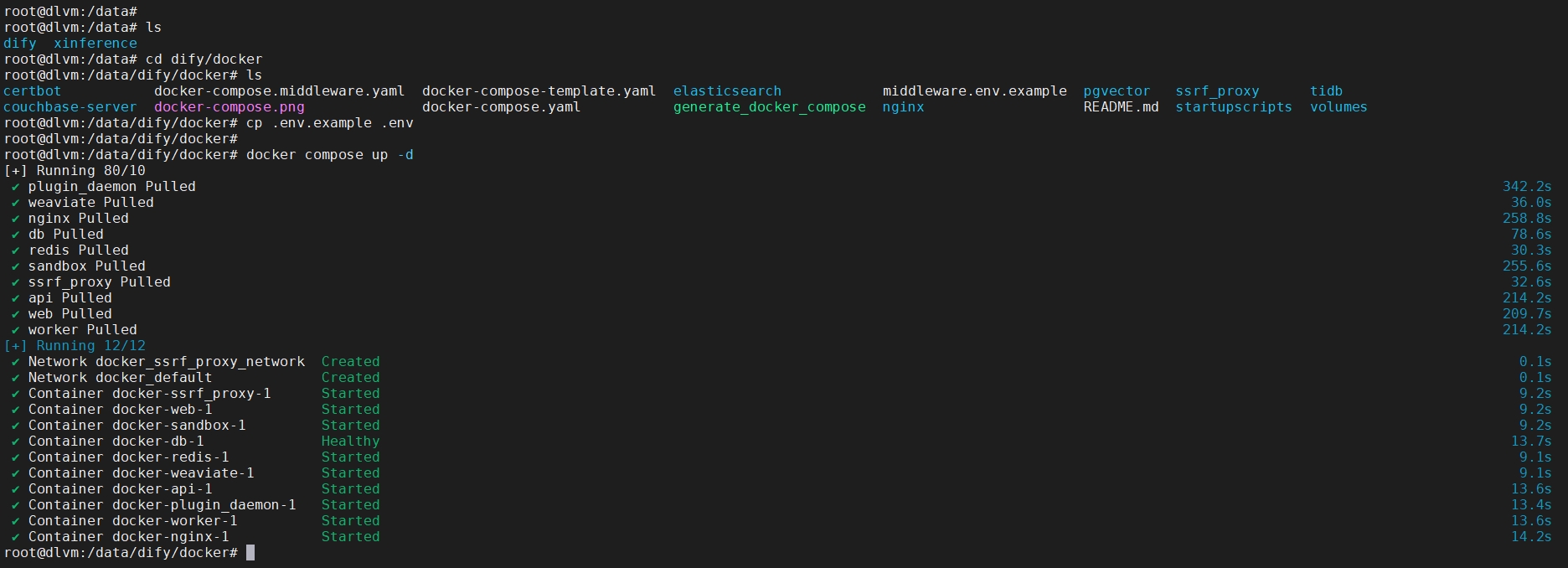
docker ps
使用http://ip_address 访问Dify平台,首次登录设置管理员邮箱,用户名密码,设置完成之后登录
模型配置
启动嵌入式模型 text2vec-base-multilingual(嵌入式模型,文本向量表示模型)
功能: 将用户查询和文档内容转换为向量表示,支持多语言文本处理。
作用: 实现文本的向量化表示,便于相似度计算。
启动重排序模型 bge-reranker-base(重排序模型)
功能: 对检索到的文档进行重排序,提升与用户查询的相关性。
作用: 优化检索结果的排序,确保最相关的文档优先。
启动LLM 模型 deepseek-r1-distill-qwen
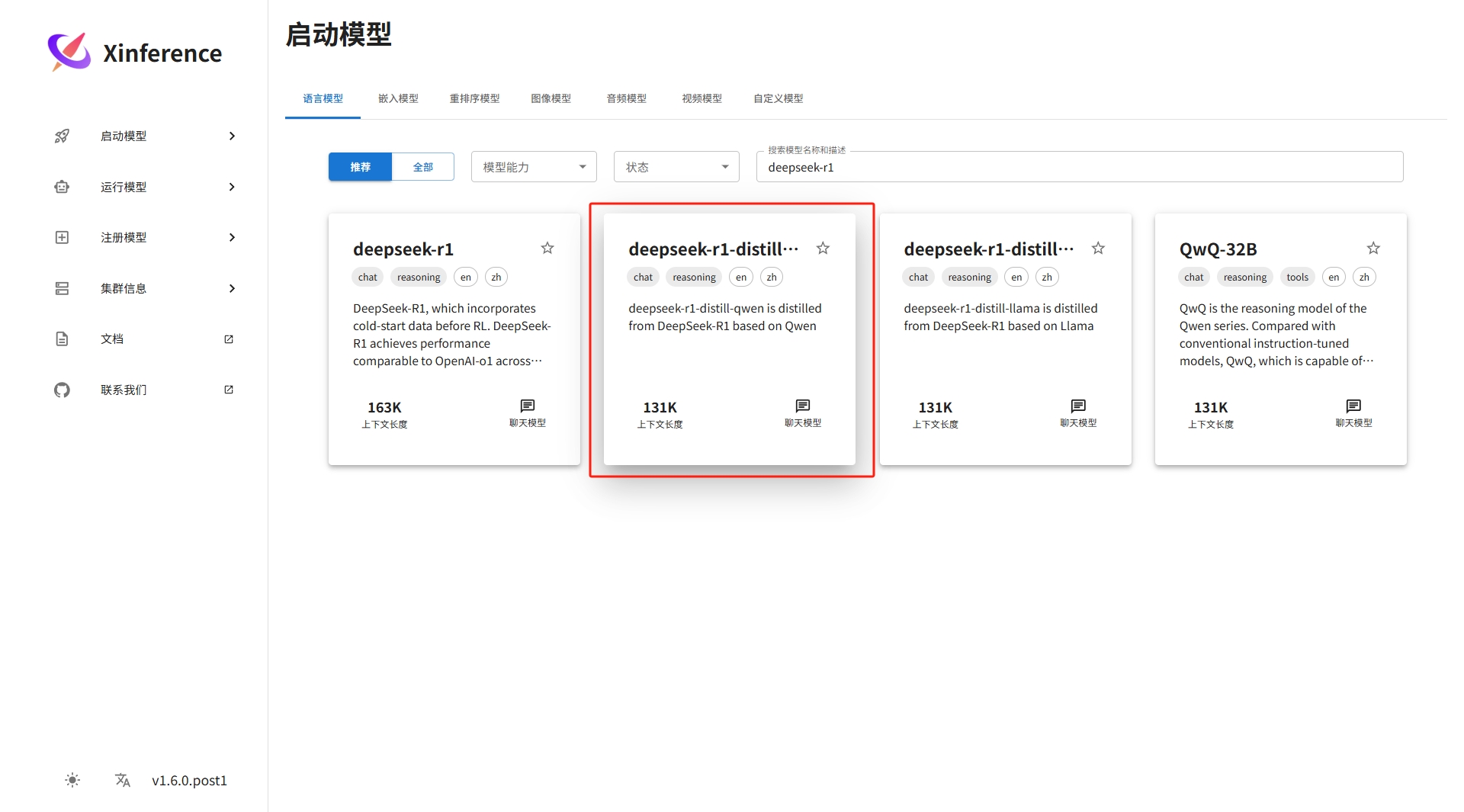
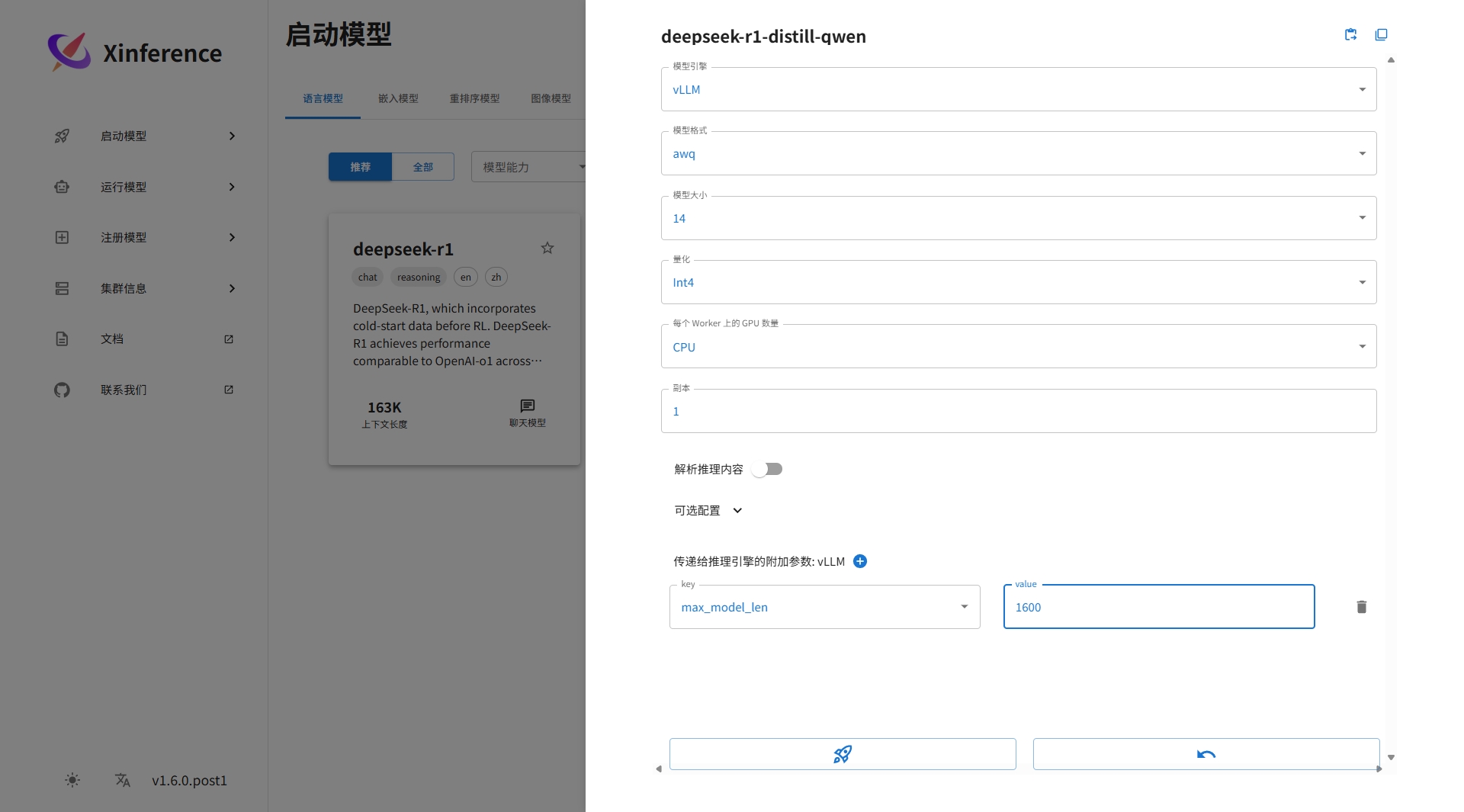
由于没有GPU,选择CPU
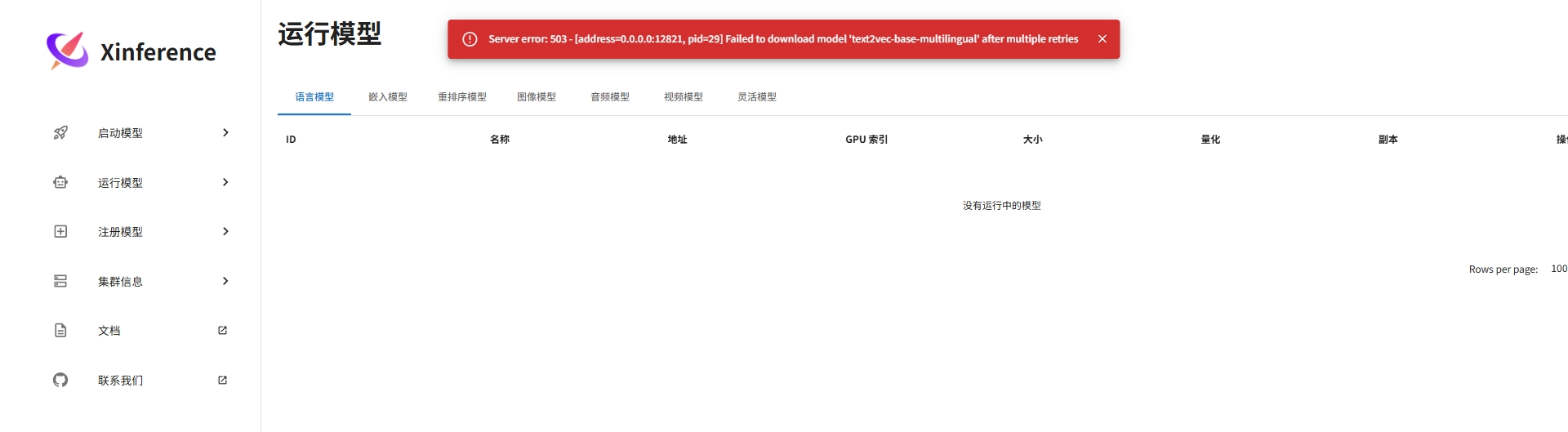
正常情况下,刚才启动的几个模型都会在运行模型列表里,由于我环境中网络的缘故导致模型无法下载。
待解决上述下载模型网络问题解决后,回到Dify平台添加模型供应商。
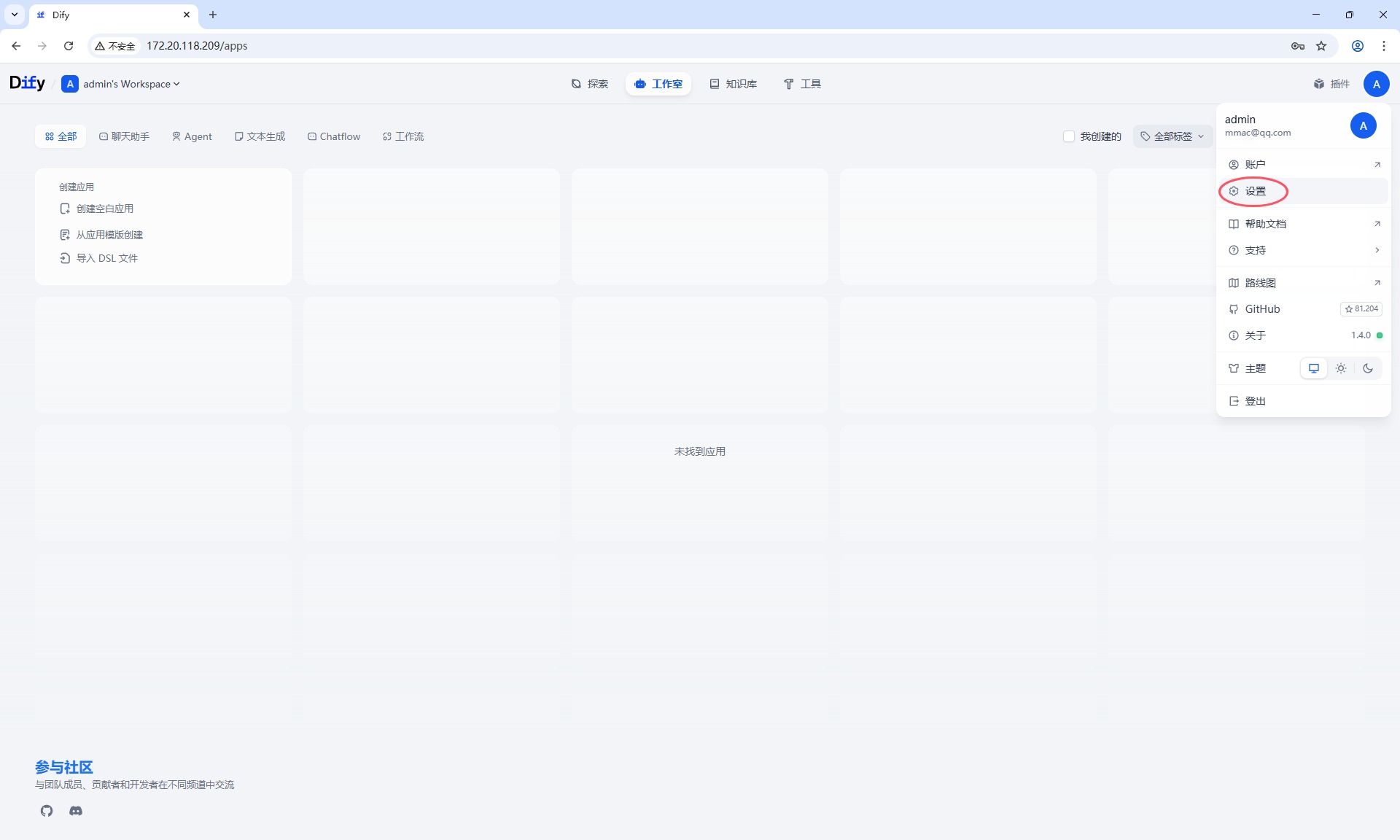
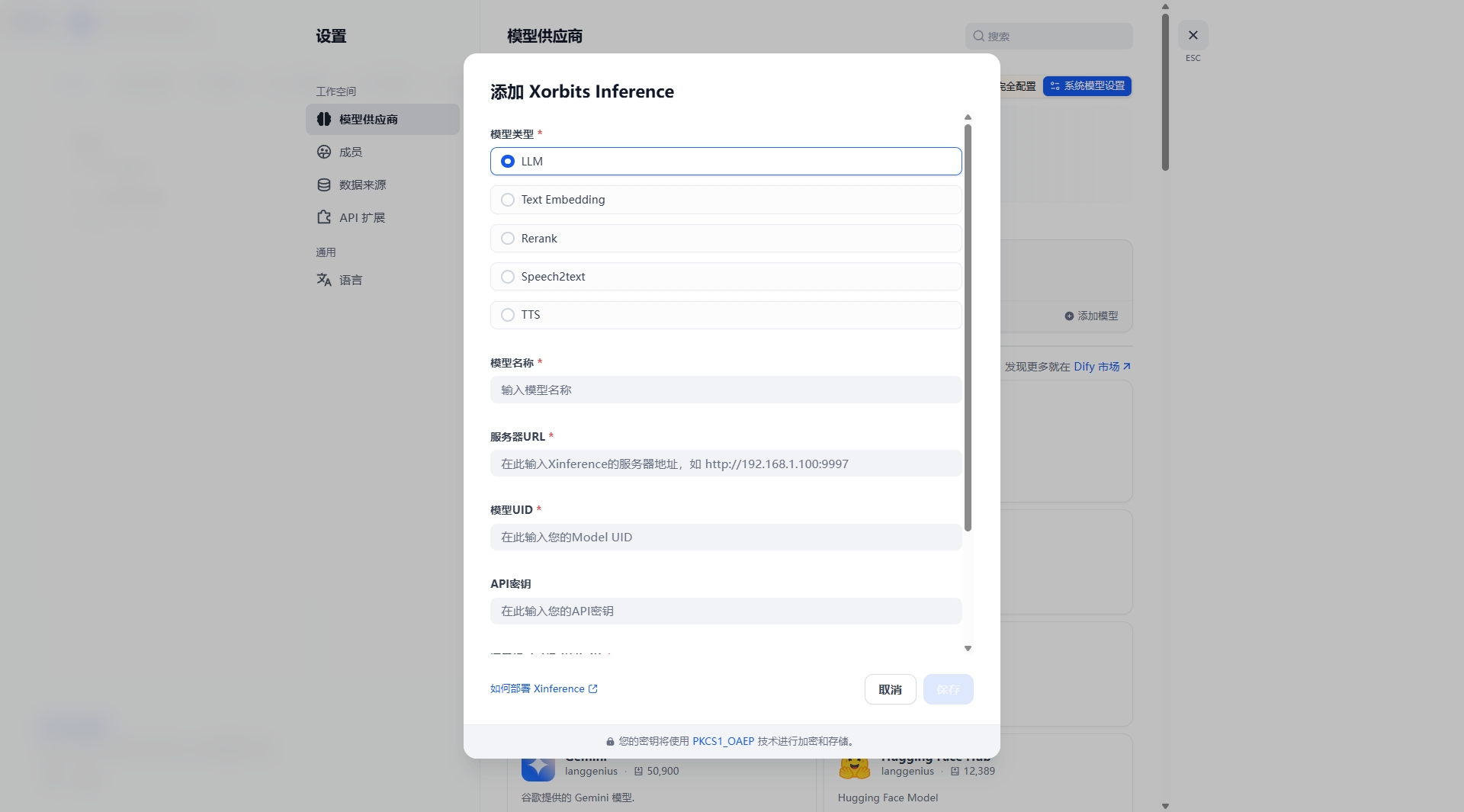
安装Xorbits Inference,添加LLM模型选择deepseek,模型名称ID,从Xinference 运行模型的位置获取,由于上面模型下载失败了,这里无法继续下去了,待解决上面模型下载失败问题后再继续更新此文!
总结
暂无总结!!

0